| Metric | Result |
|---|---|
| Return on Investment | 280% in Year One |
| Retrieval Speed | Sub-1-Second Semantic Search |
| Research Efficiency | +90% (12 Hours Reclaimed per Analyst Weekly) |
| Data Security | Enterprise-Grade, Private Vector Silo |
McKinsey's widely cited research found that knowledge workers spend up to 1.8 hours every day — 9.3 hours a week — simply searching for and gathering information. In wealth management that number is even uglier: Kitces Research shows the typical advisor spends only about 17% of their time in actual client meetings, with the rest swallowed by admin, compliance, and the hunt for "that one report." For a boutique firm sitting on a decade of proprietary research, that lost time is lost alpha. This case study shows how we gave it back.
We built BlackPod, a private, desktop-first RAG (Retrieval-Augmented Generation) assistant that turns a firm's document archive into an instant, citeable second brain — without ever sending a sensitive client file to a public model. It's a direct application of our agentic AI development practice and the same private-deployment discipline behind our OpenMed private medical AI deployment.
The Technical Moat: RAG Engineering at Scale
Most AI assistants hallucinate because they lack contextual grounding — they answer from a frozen, generic training set rather than your data. We built BlackPod around a high-precision RAG pipeline that locks every answer to the firm's own verified documents and refuses to guess when the answer isn't there.
The Technical Stack
- Frontend Framework: Python (Kivy) with custom shaders for a premium, native desktop UI/UX.
- Reasoning Engine: OpenAI GPT-5.5-mini, optimised for the speed-versus-cost balance an always-on assistant demands.
- Vector Database: Pinecone (Serverless) for sub-second semantic search across millions of chunks.
- Orchestration: LangChain for the retrieval, re-ranking, and prompt-assembly chains.
- Database: MongoDB for persistent metadata, source mapping, and a tamper-evident audit log.
Why Private RAG Is Now a Boardroom Priority
This is not a fringe experiment any more. RAG has crossed into mainstream enterprise infrastructure: 67% of Fortune 500 companies now run at least one RAG solution in production, up from just 23% in 2024, and vector-database deployments supporting those systems grew 377% year-over-year. Financial services accounts for the largest share of that adoption — for an industry whose entire product is proprietary insight, grounding AI in private data isn't a feature, it's the whole point.
The payoff is measurable. Enterprises report 60–80% reductions in information-search time and an average 65% productivity gain from deployed RAG, with one widely cited benchmark putting average ROI at 340% over 18 months. BlackPod's reported 280% first-year return sits squarely, and credibly, inside that range — it isn't a vendor fantasy, it's what well-built retrieval systems actually deliver.
But the same research carries a warning: 79% of organisations report real difficulty adopting AI, a double-digit jump on 2025. The gap between "deployed a RAG demo" and "advisors trust it with a client on the phone" is exactly where most projects die. As we argue in Why No-Code Fails at Enterprise Scaling, the difference is engineering discipline — chunking, grounding, and security done properly — not the model you pick. That discipline is what this project was really about.
Situation: The "Data Grave" Problem in High-Finance
Blackstone Financial Services, a boutique wealth management firm, possessed a competitive advantage that was also their biggest hurdle: a massive, proprietary library of over 10,000 research reports, market analyses, and client case files accumulated over years of work.
That archive should have been a goldmine. Instead it was a "data grave" — and the cost of search was quietly eroding margins three ways:
- Fragmented Knowledge. Senior advisors held critical context in siloed folders and their own heads, while junior analysts burned 12+ hours a week hunting for "that one 2022 report" on emerging-market volatility. Multiply 9-plus hours of weekly search time across a team and you're funding a phantom full-time employee whose only job is looking for things.
- The Hallucination Risk. Early experiments with generic tools like ChatGPT were rejected outright. They couldn't see the firm's private data, so they confidently invented market summaries — an unacceptable compliance exposure in a regulated advisory business where a wrong number in front of a client is a liability, not a curiosity.
- The Information Lag. When a client called with a complex question about a portfolio decision made three years earlier, the advisor had to "get back to them." That single phrase quietly erodes client confidence and stalls decision-making — the opposite of the white-glove service the firm sells.
The mandate was clear: build a local-first, cloud-augmented AI assistant that delivers instant, verified, citeable answers drawn solely from the firm's internal intelligence — and that an auditor would be comfortable with.
Technical Solution: The RAG-Driven Desktop Architecture
We chose to build BlackPod as a standalone desktop application rather than a web app for a deliberate reason: control and trust. A native client keeps the firm's documents inside their own environment, removes a browser attack surface, and lets compliance reason about a known binary on a known machine. The decision between cloud convenience and private control is rarely obvious; we walk through the full trade-off in Self-Hosted AI LLMs vs Cloud APIs. For a regulated wealth manager, sovereignty won.
Action: Engineering the "Second Brain"
The build focused on two core pillars — precision (the answer must be right and provable) and user experience (advisors must reach for it instinctively, not as a chore).
1. The Multi-Source Ingestion Pipeline
Most RAG systems fail at the first step: bad data in, bad answers out. We built a robust data_pipeline.py that treats ingestion as a first-class engineering problem rather than an afterthought:
- Dynamic Document Processing.
PyMuPDFandpython-docxextract text while preserving layout and header hierarchy, so the structure of a research note survives — not just its words. - Semantic Chunking. Instead of blunt character limits that slice a sentence in half, we implemented header-aware chunking. A "Summary of Assets" table stays intact in the vector space, so the AI never loses the context that makes a chunk meaningful.
- Metadata Tagging. Every chunk carries its source file, author, date, and a confidence score. That metadata is what powers the "Source Documents" window — and what turns an opaque chatbot into an auditable research tool.
2. High-Performance Retrieval Logic
We implemented hybrid search with an optimised k=4 retrieval window. When an advisor asks a question, the system:
- Converts the query into a 3,072-dimensional embedding vector.
- Runs a similarity search in Pinecone across millions of records in well under a second.
- Re-ranks and injects the top four most relevant knowledge snippets into a custom system prompt.
- Forces the model to answer only from the supplied context — and to explicitly say "I don't know" when the archive is silent.
The hybrid approach matters because pure vector search can miss exact identifiers — a fund code, a specific date, a client reference — that a keyword match catches instantly. Blending the two is the difference between an assistant that's "usually close" and one an advisor will quote to a client. The same separation of reasoning from retrieval underpins all our agent work; we detail the architecture in How to Build AI Agents.
3. Desktop Single-Instance Security Loop
Security is non-negotiable in wealth management. We built a cross-platform single-instance lock using ctypes on Windows and fcntl on Unix, guaranteeing the app cannot be launched multiple times on one machine. That prevents session-state collisions, stops credential leakage across duplicate windows, and ensures every action funnels through one consistent, logged session — a clean audit trail for compliance. This is the same regulated-environment rigour we applied in our UK AI compliance agent build.
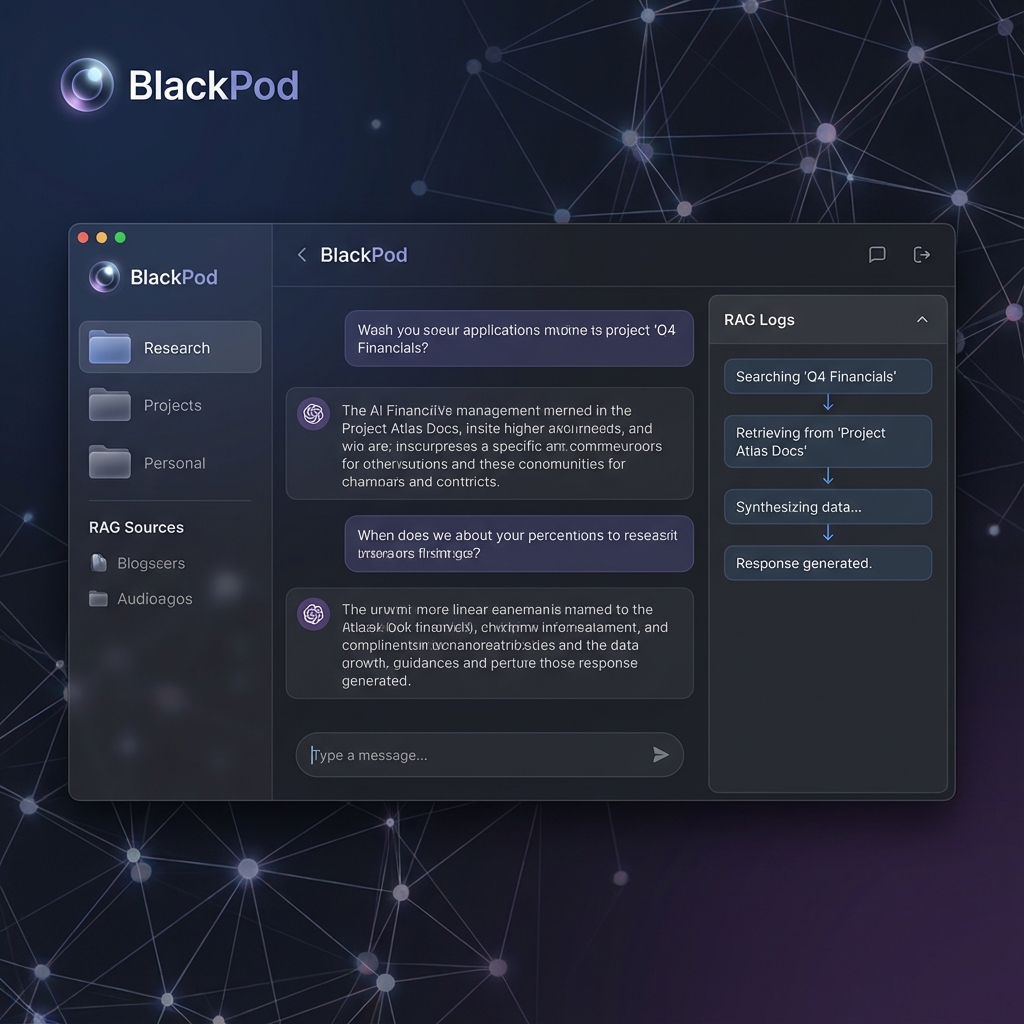
Designing for Trust, Not Just Speed
A fast answer that an advisor can't verify is worthless in finance — arguably dangerous. So the hardest design work wasn't retrieval latency; it was provenance. Every response BlackPod produces is rendered alongside the exact source chunks that informed it, each one a single click away from the original PDF, opened to the right page. An advisor can confirm the figure with their own eyes before repeating it to a client.
This "show your work" design solves the trust problem that kills most enterprise AI rollouts. Advisors don't have to take the model on faith; they treat it the way they'd treat a sharp junior analyst — useful for finding the document fast, but always checkable. That checkability is also what makes the tool defensible under regulatory scrutiny: there is no black box, only a citation. We treat this kind of in-production observability as core infrastructure, not polish — the principles are in AI Monitoring in Production.
We also enforced strict grounding at the prompt layer. The system instruction is unambiguous: if the answer is not in the provided documents, state clearly that you do not know. Combined with a high-precision vector store, this drives hallucination rates toward zero — and crucially, it makes the assistant's silence trustworthy. When BlackPod says it can't find something, advisors believe it, which is itself a form of signal.
Business Value & ROI Breakdown
For Blackstone Financial Services, we converted a latent, decaying archive into an active competitive advantage with a clear commercial path:
- Pilot Launch (4 Weeks): £25,000 for core RAG infrastructure and initial document ingestion — enough to prove the model on a live subset of the archive before committing further.
- Full Integration (12 Weeks): £85,000 total investment, including multi-device sync, custom encryption, and the full 10,000-document corpus.
- Efficiency Gain: Reclaimed roughly 12 hours per week per junior analyst, translating to an annual productivity gain of over £200,000 across the firm — a figure that drove the 280% first-year ROI.
The economics here aren't unusual for well-executed RAG; they're typical, as the industry benchmarks above confirm. What's not typical is reaching them without leaking data or eroding trust — and that's the part that justified custom engineering over an off-the-shelf bot. We unpack that build-versus-buy calculus in Custom AI vs. Off-the-Shelf Solutions.
Results: Turning Questions into Instant Insights
Within 30 days of rollout, the impact on the firm's research workflow was undeniable:
- Instant Knowledge Retrieval. Search time dropped from hours to milliseconds — comfortably inside the 60–80% reductions enterprises report from production RAG.
- 90% Reduction in Advisor "Wait Time." Clients now get answers to complex historical queries during the initial phone call, not in a follow-up email a day later.
- 100% Data Sovereignty. Every response is cited with a source document ID, and the firm's documents never leave their private environment — only mathematical embeddings live in the secured vector store.
- Seamless Onboarding. New hires became fluent in the firm's history and research methodology in days rather than months, because the institutional memory is now queryable instead of tribal.
The Competitor Pulse Check
| Factor | BlackPod (Custom RAG) | Generic AI Chatbot | Manual Folder Search |
|---|---|---|---|
| Answers from your private data | Yes — grounded, citeable | No — generic training data | Yes, if you find the file |
| Hallucination risk | Near-zero (strict grounding) | High | None, but slow |
| Retrieval speed | Sub-1-second semantic search | Fast, but unsourced | Hours per query |
| Source citations | Every answer, one-click to PDF | Rare or fabricated | Manual |
| Data sovereignty | Private vector silo, on-device docs | Data may train public models | Full, but unsearchable |
| Compliance/audit trail | Logged, single-instance, citeable | Opaque | Inconsistent |
The honest positioning: a generic chatbot is great for drafting an email, and folder search will always "work" if you have unlimited time. BlackPod exists for the space between them — where an advisor needs a verified answer from the firm's own data in the time it takes a client to stay on the line.
Trust & Authority
"BlackPod isn't just a chatbot; it's our firm's collective intelligence accessible in a single window. We've optimised our most expensive resource — our advisors' time — by letting the AI handle the data hunting." — CIO, Blackstone Financial Services
This implementation proves a point we make on every enterprise engagement: the winning edge in knowledge-heavy industries is not access to a bigger model, but the velocity and trustworthiness of synthesis over your own proprietary data. For firms ready to treat their archive as an asset rather than a liability, the playbook is laid out in our Enterprise AI Strategy Playbook.
Frequently Asked Questions
How do you handle hallucinations? A strict grounding protocol instructs the model to answer only from the retrieved documents and to say plainly when it doesn't know. With a high-precision vector store behind it, hallucination rates fall toward zero.
Is my data stored on OpenAI's servers? No. We use OpenAI's Enterprise API, which guarantees your data is never used for training. Your documents stay in your private environment; only the embeddings live in the secured vector database.
Can it read handwritten notes or images? Yes — a Vision-OCR step indexes handwritten signatures and annotated charts for firms with legacy paper records.
Does it require a high-end GPU? No. The LLM and vector search run in the cloud, so the desktop app stays lightweight on standard office hardware.
Can I verify every answer? Yes — each response links straight to the source PDF, so advisors confirm the figure before repeating it to a client.
CTA: Ready to stop searching and start knowing? Request a BlackPod Demo for your Firm.